ЗвГзЅШЁЕБЕБЭјМлИёЪ§Он
БОЮФЪЧЁЖЖЈвхЭјеОзЅШЁЙцдђЁЗвЛ ЮФЕФајЮФЃЌФЧЦЊЮФеТНВНтСЫдѕбљгУMetaStudioЖЈвхЙцдђЃЌЖјЧвВЛгУБрГЬЃЌвВВЛгУВьПДЭјвГЕФHTMLДњТыЃЌжЛашвЊЪѓБъЕуЛїВЂЖдБЛзЅШЁЕФФкШнНјааБъзЂЃЌ зЅШЁЙцдђгЩMetaStudioздЖЏЩњГЩЁЃЖјЧвЃЌЮвУЧЛЙПДЕНЃКдкMetaStudioЕФзЅШЁНсЙћЪфГіДАПкжавбОЯдЪОСЫЭјеОзЅШЁНсЙћЁЃЕЋЪЧЃЌЮвУЧзЅШЁЕБЕБЭј ЩЬЦЗМлИёЪ§ОнЕФФПЕФЪЧНЈСЂБШМлЯЕЭГЃЌШчЙћДгMetaStudioЕФзЅШЁНсЙћДАПкжаЪжЙЄНЋНсЙћЪ§ОнПНБДГіРДЯдШЛЪЧВЛЗћКЯздЖЏЛЏДІРэвЊЧѓЕФЃЌБОЮФвЊНтОівдЯТЮЪ ЬтЃК
- ЗвГзЅШЁЫљгаЩЬЦЗаХЯЂ
- здЖЏБЃДцзЅШЁНсЙћ
- жмЦкадздЖЏЛЏКЭдіСПзЅШЁ
1 ЖЈвхЗвГзЅШЁЙцдђ
НєНгзХЁЖЖЈвхЭјеОзЅШЁЙцдђЁЗЕФВйзїВНжшЃЌЕЋЪЧЃЌетвЛДЮЮвУЧаоИФвЛЯТжїЬтУћвдЪОЧјБ№ЃК
- жїЬтУћЃКdemo_DD_list_1
зЂЃКБОЮФЖЈвхЕФаХЯЂНсЙЙвбОЩЯдиЕНЗўЮёЦїСЫЃЌЖСепПЩвдАДееЁЖМгдиаХЯЂНсЙЙЁЗНВЪіЕФЗНЗЈМгдиетИіаХЯЂНсЙЙЃЌвдЬсИпдФЖСБОЮФЕФаЇЙћЁЃ
зЂвт1ЃКФПБъЭјвГНсЙЙИФБфКѓПЩФмЛсгАЯьвдЧАЖЈвхКУЕФаХЯЂНсЙЙЃЌШчЙћМгдиВЛГЩЙІЃЌПЩвдВЮееЁЖаоИФЪЇаЇЕФзЅШЁЙцдђЁЗвЛЮФЖдаХЯЂНсЙЙНјаааоИФЁЃ
зЂвт2ЃКШчЙћИУаХЯЂНсЙЙМгдиВЛГЩЙІЃЌПЩФмЛЙгаБ№ЕФдвђЃЌЁЖзЅШЁЭјвГЮФзжФкШнЦЌЖЯЁЗИјГіСЫЯъЯИЗжЮі
МйЩшЮвУЧвбОАДееЁЖЖЈвхЭјеОзЅШЁЙцдђЁЗЕФВйзїВНжшЖЈвхСЫЕБЕБЭјЩЬЦЗМлИёзЅШЁЙцдђЃЌвђЮЊGSMЪжЛњгаКмЖрЃЌЗжГЩСЫЖрвГЃЌНгЯТРДЮвУЧЯыЗвГзЅШЁУПвЛвГЩЯЕФЪжЛњЪ§ОнЁЃЕБЮвУЧфЏРРЭјвГВЂЗвГЪБЃЌЮвУЧашвЊЕуЛївЛИіБэЪО“ЯТвЛвГ”ЕФГЌСДНгЛђепАДХЅЃЌЕМКНЕНЯТвЛвГЃЌGooSeekerЃЈMetaSeekerЕФПЊЗЂЭХЖгЃЉГЦетИіГЌСДНгЛђепАДХЅЮЊЯпЫїЃЌОЭЪЧЭјТчХРГцЕМКНХРааЕФЯпЫїЁЃЯпЫїгаКмЖржжЃЌБОЮФжЛгУЕНМЧКХЯпЫїЃЌЦфЫќРраЭВЮМћЁЖЛёШЁЭјеОзЅШЁЯпЫїЁЗЁЃ
1.1 ДДНЈЯпЫї
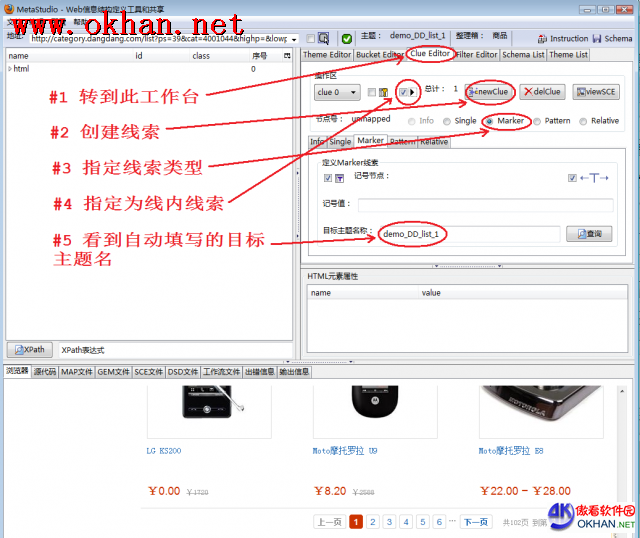
ЭМ1ЯдЪОСЫдѕбљДДНЈвЛИігУгкЗвГЕФЯпЫїЃЌгаШчЯТВНжшЃК
- зЊЕНClue EditorЙЄзїЬЈ
- ЕуЛїnewClueАДХЅЃЌДДНЈвЛИіЯпЫї
- ЕуЛїMarkerРраЭЃЌЩшЖЈЮЊМЧКХЯпЫїЃЌ“ЯТвЛвГ”зжбљОЭЪЧМЧКХ
- жИЖЈЮЊЯпФкЯпЫїРраЭЁЃ
- гЩгкВЩгУЯпФкЯпЫїЃЌФПБъжїЬтУћБЛздЖЏЬюШыЃЌЖјЧвФПБъжїЬтУћгыБОжїЬтУћЯрЭЌЃЌПЩвдЪжЙЄаоИФФПБъжїЬтУћЃЌЕЋЪЧЃЌЗвГзЅШЁЪБВЛгІИУаоИФЁЃЪВУДЪБКђаоИФЃПВЮМћЁЖзЅШЁAJAXЭјеОЁЗНЬГЬЁЃ
ЗвГзЅШЁЪБЃЌЕМКНЕНЯТвЛвГЕФЯпЫївЛАуЖЈвхГЩЯпФкЯпЫїЃЌДњБэ“ЯТвЛвГ”ЕФЭјвГЭјжЗОЭВЛЛсБЛМЧТМЯТРДЃЌжЛЪЧСйЪБгУРДЗвГЃЌетбљПЩвдДѓДѓЬсИпзЅШЁЫйЖШЁЃШчЙћМЧТМЯТРДЛЙгаИіЛЕДІЃКзіМлИёИњзйМрВтЪБашвЊУПЬьжиИДзЅШЁЫљгаЩЬЦЗМлИёЃЌУПДЮЖМДгЕквЛвГЭљЯТЗвГПЩвдШЗБЃВЛвХТЉвВВЛжиИДЁЃШчЙћМЧТМСЫжаМфвГЕФЭјжЗЃЌФЧУДЃЌжиИДзЅШЁЪБгаЕФДгЕквЛвГПЊЪМЗвГЃЌгаЕФДгЕкNвГПЊЪМЗвГЃЌДцдкДѓСПжиИДЁЃ
ЪВУДЪБКђВЛЪЙгУЯпФкЯпЫїЃЌВЮМћЁЖЗжМЖзЅШЁЁЗНЬГЬЁЃ
1.2 ЯпЫїгГЩф
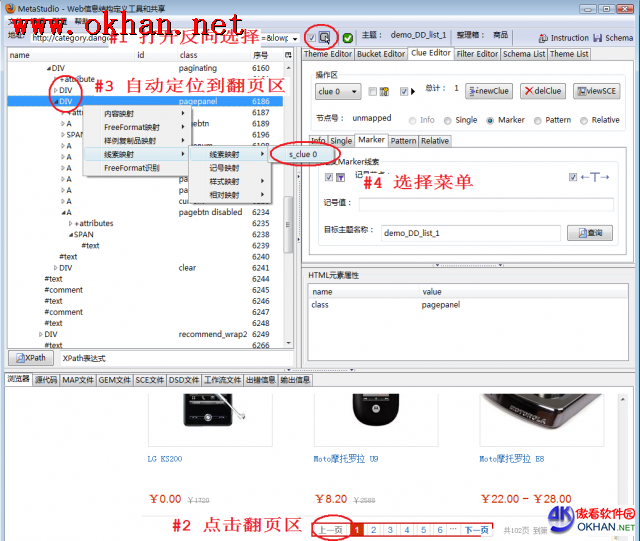
ЭМ2ЯдЪОСЫЯпЫїгГЩфЙ§ГЬЃЌвВОЭЪЧИцЫпMetaStudioДгФФРязЅШЁГЌСДНгЕФURLЕижЗЁЃгаШчЯТВНжшЃК
- ДђПЊЗДЯђбЁдёПЊЙиЁЃВЮМћЁЖЖЈвхЭјеОзЅШЁЙцдђЁЗЕкШ§ВНЁЃ
- дкФкЧЖфЏРРЦїЩЯЕуЛїЗвГЧј
- ФмЙЛПДЕНMetaStudioздЖЏевЕНСЫЗвГЧјЕФDOMНкЕуЃЌФњашвЊевЕНДњБэећИіЗвГЧјПщЕФФЧИіDOMНкЕуЃК@class=pagepanelЕФФЧИіDIV
- дкDOMЪгДАжаЕуЛїЪѓБъгвМќЃЌбЁдёЯпЫїгГЩфВЫЕЅЁЃЯъЯИЫЕУїВЮМћЁЖЖЈвхГЌСДНгзЅШЁЙцдђЁЗ
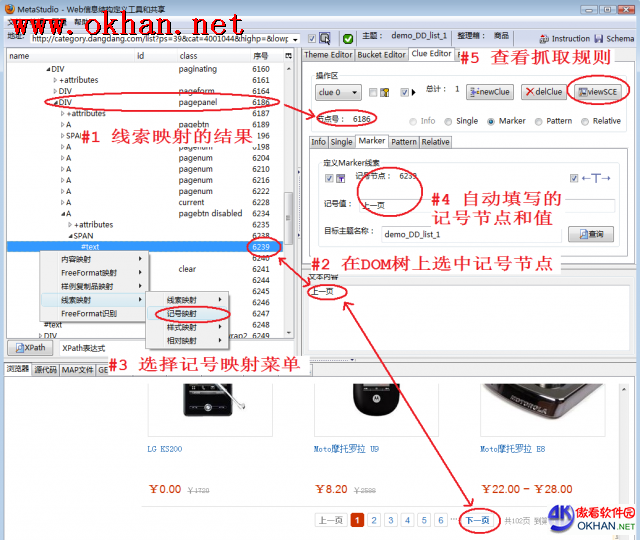
ЭМ3ЯдЪОдѕбљгГЩфМЧКХЃЌгаШчЯТВНжшЃК
- ОЙ§ЭМ2ЕФВНжшЃЌПЩвдПДЕНЯпЫїгГЩфЕФНсЙћ
- дкDOMЪїЩЯевЕНКЌгаМЧКХ“ЯТвЛвГ”ЕФФЧИіTEXTНкЕуЃЌВЂбЁжаЫќ
- дкDOMЪїЪгДАЩЯЕуЛїЪѓБъгвМќЃЌбЁдёЕЏГіВЫЕЅЯюМЧКХгГЩф
- MetaStudioЛсздЖЏНЋМЧКХНкЕуКХКЭМЧКХжЕЬюШы
- ЕуЛїviewSCEАДХЅПЩвддкMetaStudioЯТВПЕФSCEЮФМўДАПкжаПДЕНЯпЫїзЅШЁЙцдђЁЃ
1.3 БЃДцзЅШЁЙцдђ
ЭЌЁЖЖЈвхзЅШЁЙцдђЁЗНЬГЬвЛбљЃЌЕуЛїMetaStudioЕФЙЄОпЬѕЩЯЕФschemaАДХЅНЋЖЈвхКУЕФаХЯЂНсЙЙЩЯдиЕНЗўЮёЦїЃЌвдБуФмЙЛЫцЪБЫцЕиЪЙгУMetaSeekerдЦМЦЫузЅШЁЗўЮёЁЃ
жСДЫЃЌвЛИіЭъећЕФЭјеОзЅШЁЙцдђЖЈвхЭъСЫЃЌМШзЅШЁвГУцЩЯЫљгаЩЬЦЗаХЯЂЃЌвВЗвГЕНКѓајЫљгаЭјвГзЅШЁИќЖрЩЬЦЗЁЃЯТУцНВНтдѕбљЪЙгУетИізЅШЁЙцдђЁЃ
2 DataScraperХњСПзЅШЁ
МйЩшвбОГЩЙІАВзАСЫDataScraperЃЈВЮПМЁЖАВзАЭјеОзЅШЁЯЕЭГMetaSeekerЁЗЃЉЃЌЦєЖЏЗНЗЈгыMetaStudioЯрЭЌЁЃ
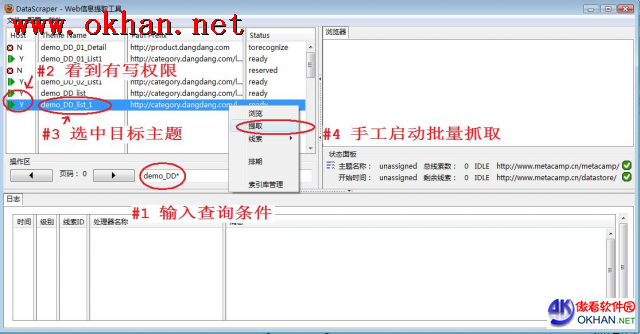
ЭМ4ЯдЪОдѕбљЪжЙЄЦєЖЏХњСПзЅШЁЃЌгаШчЯТВНжшЃК
- ЪфШыВщбЏЬѕМўЃЌдкжїЬтСаБэжаЯдЪОЗћКЯВщбЏЬѕМўЕФжїЬтУћЁЃПЩвдЪЙгУЭЈХфЗћ*ЃЌЖјЧвЭЈХфЗћПЩвдГіЯжЖрИіЁЃ
- ТЬЩЋШ§НЧБъжОЫЕУїЕБЧАгУЛЇЖдетИіжїЬтгЕгаШЋВПШЈЯоЃЌФмЙЛжДаазЅШЁВйзї
- бЁжажїЬтdemo_DD_list_1
- дкжїЬтСаБэЩЯЕуЛїЪѓБъгвМќЃЌбЁдёЕЏГіВЫЕЅЯюЬсШЁЃЌЛсЕЏГівЛИіЖдЛАПђЃЌЪфШыЯпЫїЪ§СПЁЃБОР§дкЖЈвхзЅШЁЙцдђЪБздЖЏЩњГЩСЫвЛИіЯпЫїЃЌЫљвджЛФмЪфШы1ЃЌЪфШыЦфЫќЪ§зжУЛгавтвхЁЃ
ШБЪЁЧщПіЯТЃЌDataScraperВЩгУЦеЭЈзЅШЁФЃЪНЃЌЫйЖШКмТ§ЃЌШчЭМ5ЫљЪОЃЌВЛЙДбЁЦеЭЈФЃЪНвдЬсИпЫйЖШЁЃШчЙћФњЙКТђСЫЦѓвЕАцЃЌЛЙгаНјвЛВНЬсИпЫйЖШЕФбЁЯюЃЌВЮМћЁЖдѕбљЬсИпВЩМЏОЉЖЋЩЬГЧЩЬЦЗМлИёЕФЫйЖШЁЗЁЃ
3 ЮФМўДцДЂФПТМНсЙЙ

ЭМ6ЪЧвЛЬЈдЫааMetaStudioКЭDataScraperЕФМЦЫуЛњЕФФПТМНсЙЙЃЌЕБЧАWindowsЕЧТМгУЛЇЪЧworkЃЌМИИіжївЊЕФФПТМКЭЮФМўЪЧЃК
- workЪЧЕБЧАWindowsЕЧТМеЪКХЃЌдкетИіФПТМЯТMetaStudioКЭDataScraperЗжБ№ДДНЈИїздЕФХфжУЮФМўЃК.metastudio.confКЭ.datascraper.confЃЌЖМЪЧЮФБОЮФМўЃЌПЩвдБрМаоИФ
- .datascraperЪЧDataScraperДДНЈЕФФПТМЃЌгУгкДцДЂШежОЮФМўКЭжмЦкадздЖЏзЅШЁжИСюЮФМў
- DataScraperWorksЪЧDataScraperДДНЈЕФФПТМЃЌгУгкДцДЂзЅШЁНсЙћЃЌвджїЬтУћНЈСЂзгФПТМЃЌзЅШЁНсЙћЪЧXMLЮФМўЃЌДцдкИїздЕФзгФПТМЯТЁЃ
4 жмЦкадздЖЏЛЏзЅШЁ
зЅШЁЕБЕБЭјЩЬЦЗМлИёЪ§ОнНЈСЂБШМлКЭМлИёИњзйЯЕЭГЪБЃЌашвЊЖЈЦкжиИДзЅШЁЫљгаЩЬЦЗЕФМлИёЃЌР§ШчЃЌУПЬьзЅШЁвЛБщЃЌеташвЊХфжУжмЦкадзЅШЁжИСюЮФМўЃЌетЪЧвЛИі XMLЮФМўЃЌДцДЂдк.datascraperФПТМЯТЃЌУћГЦЪЧcrontab.xmlЁЃРяУцПЩвдХфжУЕФВЮЪ§КмЖрЃЌР§ШчЃЌХХЦкЁЂЪЧЗёдіСПзЅШЁЁЂХњДЮДѓаЁЁЂЪЧЗё здЖЏЩЯдиЕНЗўЮёЦїЃЈашвЊАВзАХфЬзЕФгяСЯПтЙмРэЯЕЭГMetaCorporaЛђепЦѓвЕОКељЧщБЈЯЕЭГSliceProfileЃЉЕШЕШЃЌашвЊбаЖС ЫЕУїЪщЁЃ
ЪЙгУжмЦкадзЅШЁжИСюЮФМўЛЙФмЙЛЭЌЪБЦєЖЏЖрИіЯпГЬЃЌЭЌЪБЖдЖрИіжїЬтИљОнХХЦкВЮЪ§ЖЈЪБжДааЁЃ
TagsЃКЙЄОпШэМў
зїепЃКFuller
- КУЕФЦРМлЁЁШчЙћФњОѕЕУДЫЮФеТКУЃЌОЭЧыФњ
0%(0) 

- ВюЕФЦРМлЁЁШчЙћФњОѕЕУДЫЮФеТВюЃЌОЭЧыФњ
0%(0) 