抓取手机游戏网页内容
也许受此手机游戏网站的动作游戏所吸引,想为自己做一个手机动作类游戏搜索引擎或者仅仅是个简单的索引库,那么网页内容抓取软件工具包MetaSeeker就派上用场了,首先使用工具包中的MetaStudio工具定义抓取规则,从加载样本页面到生成游戏抓取规则,全部在MetaStudio图形化界面上操作,自动生成的内容抓取规则交给DataScraper,后者爬行网站并抓取网页内容。现在,我们要抓取这个网站上的动作类手机游戏列表,这是最简单的情形,有下面几步:
操作步骤
运行MetaStudio
运行MetaStudio
加载样本页面
在MetaStudio的URL地址输入框输入:http://www.cn3gw.com/html/game/dongzuo/,回车后,该页面作为样本页面被加载,MetaStudio自动将网页内容的DOM树显示出来,如图1
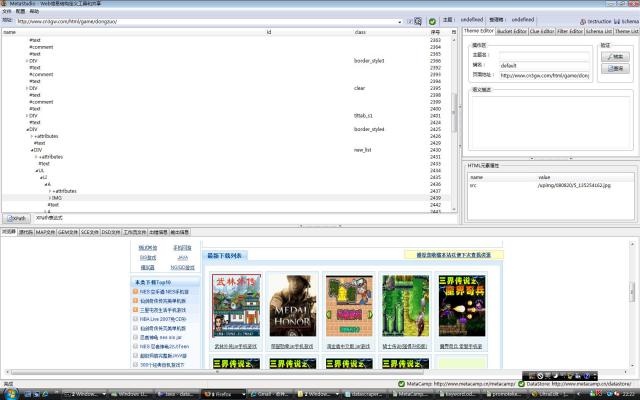
图1(放大)
命名主题
在Theme Editor工作台上命名主题,本例为:demo_game_list_basic
定义内容抓取规则
在Bucket Editor工作台上创建整理箱并定义内容抓取规则。此网页的游戏列表显示的有关游戏的信息很少,实际上,该网页只是一个门户,用户在此找到喜欢的游戏后点击此游戏的超链接进入详细的游戏页面。所以,从该网页上抓取内容的整理箱结构很简单,主要抓取游戏名称和指向详细的游戏页面的超链接。如图2
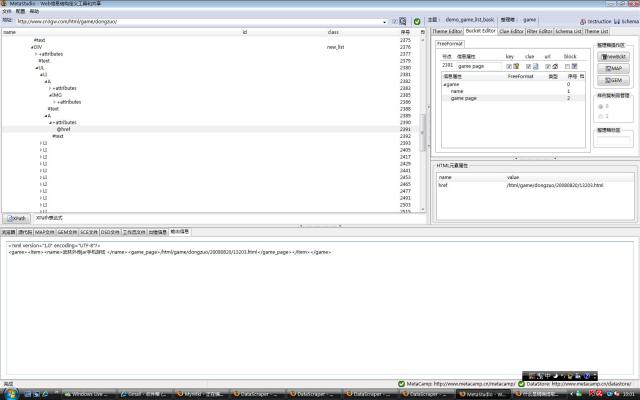
图2(放大)
怎样定义网页内容抓取规则在MetaStudio用户手册中说明,图2是执行了数据映射后的整理箱结构,将DOM中的text节点(编号2392)映射给name信息属性;将@href节点(编号2391)映射给game page节点。至此,可以验证抓取结果了,点击MAP按钮,可以看到下栏转换到MAP文件窗口,再点击右边的TestThis按钮,即显示抓取结果(如图2)。
只抓取到一个游戏实例,显然不是我们的目的,怎样抓取列表中所有的游戏信息?这就是要指导MetaStudio计算出多实例重复规则。 MetaStudio提供两种途径提取多实例:1,FreeFormat技术;2,样例复制品。前者在以后章节讲解,本网页上的FreeFormat标志 很少,我们采用样例复制品方法。
样例复制品使用方法参见MetaStudio用户手册,图3显示映射完样例复制品后的界面,样例复制品映射到容器节点game上,右栏样例复制品管理栏中显示DOM节点号2381和2393作为样例(都是HTML LI元素)。验证抓取结果,看到整个列表都抓到了(图3)。
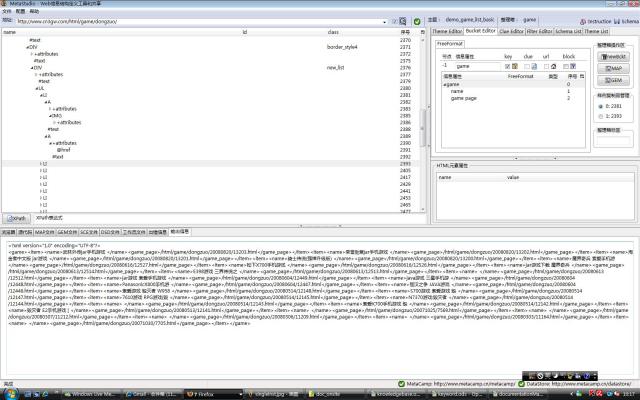
图3(放大)
注意:从图2可以看出,两个信息属性都设置了key特性,如果要使用周期性提取的加速机制,一个整理箱至少有一个信息属性设置key特性,否则会报错。
定义下一层抓取线索
抓取这个网页的主要目的是想进入每个游戏的详细信息页面,抓取详细内容,也就是说从当前这个网页上抓取超链接,等网络爬虫下一轮调度时利用现在抓到 的超链接专门抓取游戏详细信息,从图2可以看到,给信息属性game page制定特性时勾选了clue和url,表示要从game page信息属性中将超链接拿出来,作为下一层内容抓取的线索。
转到Clue Editor工作台,可以看到已经自动建立了一个Info类的线索,它对应于game page信息属性。同样我们要给他命名主题,起名为demo_game_basic,不要与当前主题名相同,因为分别表示不同的语义。
另外,这个列表页分页显示,所以,要指导网络爬虫翻页抓取,我们利用“下一页”字符串作为标志翻页,定义一个Marker(记号)类线索,进行记号映射,该线索的主题名与当前的相同,而且是in-thread类线索。图4是映射后的界面。
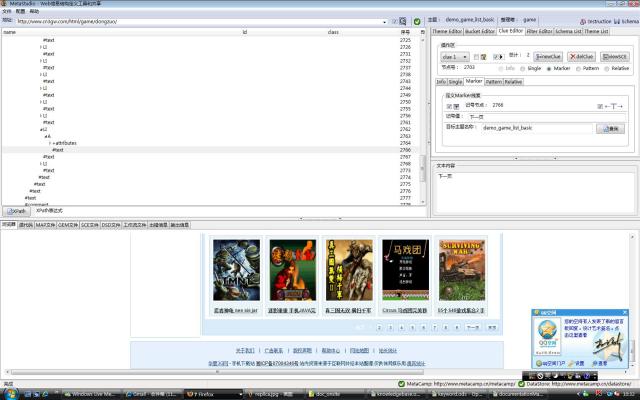
图4(放大)
至此,整个信息结构定义完了,需要上载到服务器供DataScraper使用。
总结
抓取列表页一般不是最终目的,而是为了抓取进入详细游戏信息的网页的超链接,因此,至此,我们构造了这样一个网络爬虫网络(图5)。

图5(放大)
图5上demo_game_basic主题的背景色是白色的,表示还没有为其定义信息结构,有两种方法定义demo_game_basic的信息结构:
- 等待DataScraper抓取了demo_game_list_basic主题后使用MetaStudio的主题识别功能将demo_game_basic主题的信息结构定义全。
- 为demo_game_basic选择一个样本页面,按照本文所述过程再为demo_game_basic定义信息结构即可。
两种方法效果一致,根据用户喜好选择,不再赘述。
回顾:这就是在做网站设计的逆向工程。
下一步做什么
也许我们的兴趣不仅仅是动作类游戏,其它游戏也想要,怎样做?下一节讲解。
Tags:工具软件
作者:Fuller
- 好的评价 如果您觉得此文章好,就请您
0%(0) 

- 差的评价 如果您觉得此文章差,就请您
0%(0) 