选取合适的FreeFormat标志抓取Web页面
基于FreeFormat的 Web页面抓取是MetaSeeker的独一无二的特征,除了利于建设Web信息语义标注知识库以外,可以大大提高页面抓取的准确度和适应性。 FreeFormat利用了目标页面上的标志性信息,例如,HTML元素的class属性和id属性等,对其进行语义标注,并用来定位页面内容,如果使用 得当,虽然目标页面结构发生比较大的调整,原有的信息抓取规则仍然适用。
但是,选择FreeFormat标志需要技巧,主要参照以下原则:
原则1:靠近原则
在DOM树上,尽量选用最靠近被抓取内容的FreeFormat,因为越靠近,被抓取内容所在的HTML DOM节点和FreeFormat节点之间HTML结构变化的可能性越小,Web页面抓取规则适应性越高。例如,图1和图2是两个相对的情形。
图1是ebay的页面,class和id属性特别丰富,选择灵活度很高,靠近原则是首要原则,例如,本主题为了抓取产品列表,DOM节点编号2488的的HTML元素代表一条产品记录,将其class=lview sml作为FreeFormat映射给goods信息属性(请 看MetaStudio右栏的整理箱结构),达到提取多实例的目的。然后,将编号是2512的节点的class=v4lnk作为FreeFormat标志 映射给name和page,达到精确定位的目的,在class=v4lnk节点以上有很多带有class和id的节点,没有选用它们,是为了符合靠近原 则。
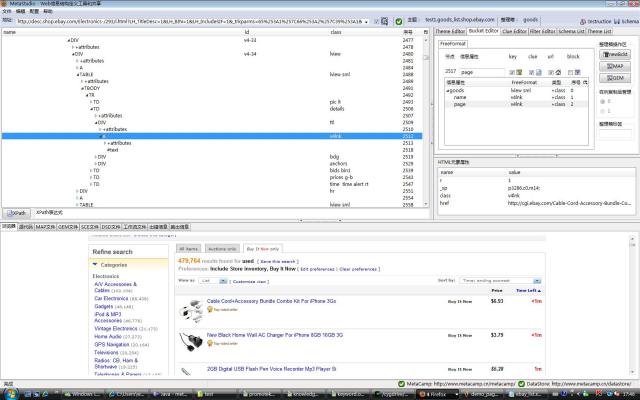
图1(放大)
相反,图2是feiku的页面,页面上的class和id属性不多,根本没有选择的余地。本主题(demo_paging_feiku_List) 是为了抓取网络小说的列表,从中抓取指向小说内容页面的超链接,从而可以进一步抓取小说内容。在列表中每篇小说的信息都放在一个HTML UL元素中(DOM节点编号:915),该元素没有可利用的FreeFormat标志,再往上有一个@id=CrListText的节点,很可惜,这个节 点包含的内容是整个列表,不能映射到信息属性List上(请看右栏整理箱结构),所以采用了样例复制品映射。但是,图3所示的页面抓取规则仍然自动使用了@id=CrListText这个标志,这是MetaStudio的算法自动选用的,希望能够在没有使用FreeFormat映射的情形下尽量使抓取规则更有适应性。
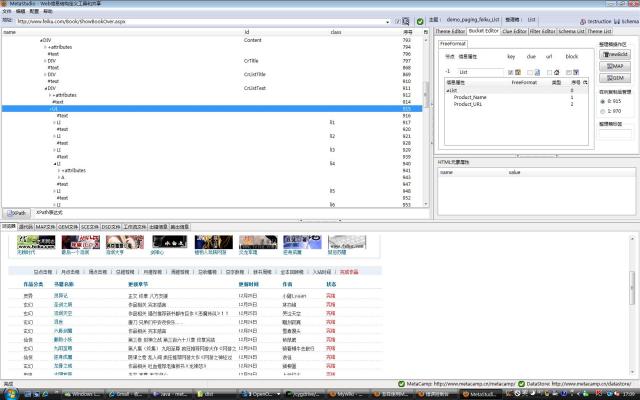
图2(放大)
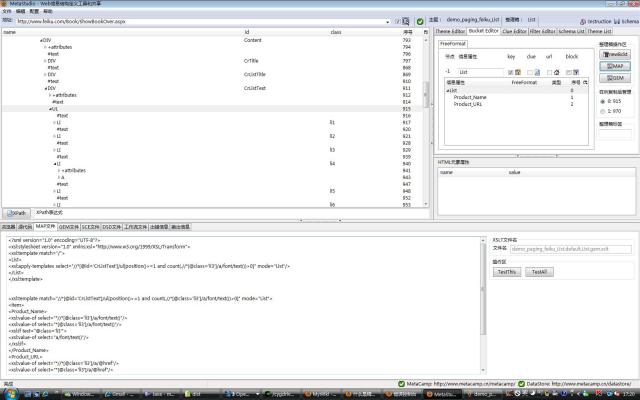
图3(放大)
用户仍然可以控制MetaStudio的自动选用标志的倾向,参见微调抓取网页数据的规则一文,微调时要遵照原则一,选用最靠近的FreeFormat。
原则2:无歧义原则
原则1并不总是有效,如图4所示,抓取demo_paging_feiku_List主题的翻页线索时,容易出问题,虽然不支持FreeFormat线索映射,但是,MetaStudio计算抓取规则时仍然尽量自动选择合适的FreeFormat标志,同样可以干预它的算法,通过点击系统菜单配置->首选项,切换到线索定位那个tab,同样微调线索抓取规则。缺省是偏好id,如果保持这个缺省值,生成的线索提取规则是合适的,如图5中的红圈。如果选用任何一个,将会选择编号是2768的那个@class=mypager,虽然符合原则1,但是,由于mypager在网页上出现很多次,容易造成MetaSeeker错误定位被抓取的超链接。
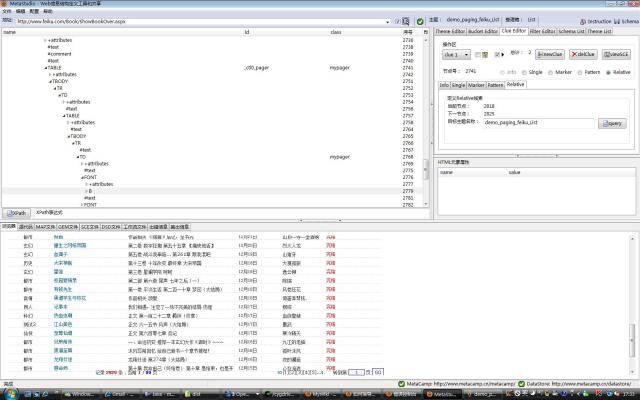
图4(放大)
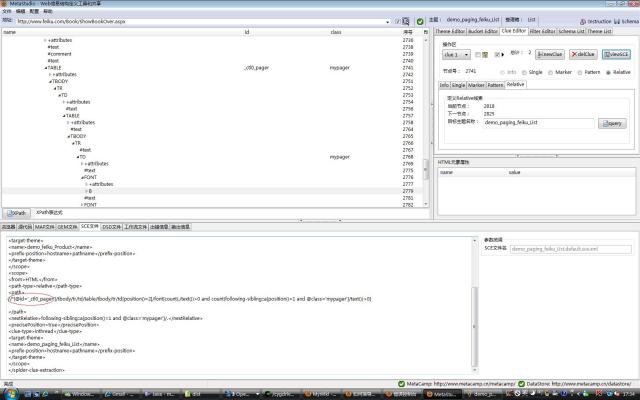
图5(放大)
一个相反的例子是主题demo_paging_mydown,用于从Web上抓取软件信息,如图6所示,如果采用偏好id, 将自动选择编号是2122的节点的id=myTab2_con0作为FreeFormat标志,该标志代表整个软件列表,离表示翻页的那个HTML块 (class=mdpage)很远,当翻到第二页时,因为id=myTab2_con0和class=mdpage之间的结构变化了,无法正确抓取超链 接,相反,如果采用任何一个,就会就近选择class=mdpage作为FreeFormat标志。
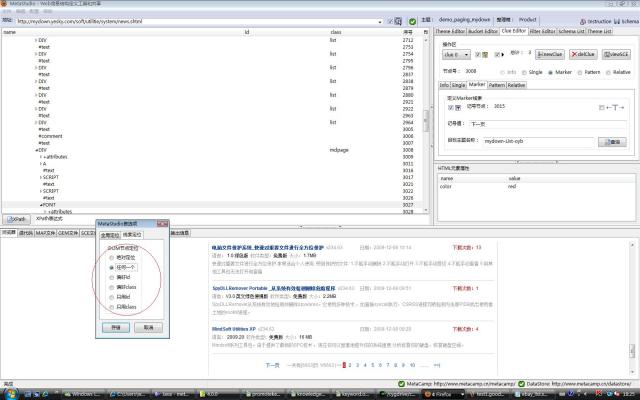
图6(放大)
总结
Web页面抓取软件工具包MetaSeeker提供了最大的灵活性,用户需要通过尝试找出最符合当前网站的首选项和配置。
Tags:行业软件
作者:Fuller
- 好的评价 如果您觉得此文章好,就请您
0%(0) 

- 差的评价 如果您觉得此文章差,就请您
0%(0) 